 東京科学大学 研究
東京科学大学 研究メタゲノム由来ゲノムを収集・整理した統合データベース「Microbiome Datahub」を開発
21万ゲノム以上のMAG配列と環境・機能情報を統合し、微生物研究を加速
【注目の成果:共同研究・産学連携のためのチェックポイント】
 | データ駆動型の微生物学や未知の有用タンパク質探索の基盤として貢献することが期待 |
【産学連携対象 全学共通分野 Discovery Saga】
【Sagaキーワード】
品質評価/インターフェース/データ駆動/ユーザインターフェース/アノテーション/オントロジー/クラスタリング/スーパーコンピュータ/深層学習/人工知能(AI)/がん研究/免疫機能/微生物群集/タンパク質構造/塩基配列/系統分類/生存戦略/生物群集/活性汚泥/ダイナミクス/環境情報/構造予測/腸内フローラ/麹菌/発酵/微生物学/胞子形成/rRNA/ゲノム配列/16S rRNA/リンパ腫/土壌/微生物/アミノ酸配列/ゲノム情報/メタゲノム解析/細胞形態/ゲノム解析/メタゲノム/大腸/腸内環境/がん化/発がん/T細胞/アミノ酸/大腸がん/白血病/ゲノム/メタボローム/メタボローム解析/遺伝学/遺伝子/遺伝子変異/細菌/細菌叢/早期発見/腸内細菌/腸内細菌叢/標準化
2026年4月2日 公開
概要
東京科学大学(Science Tokyo) 生命理工学院 山田拓司教授、情報・システム研究機構 国立遺伝学研究所の森宙史准教授、自然科学研究機構 基礎生物学研究所の内山郁夫准教授、京都大学 化学研究所 松井求助教を中心とする共同研究グループ(国立遺伝学研究所、基礎生物学研究所、東京科学大学、京都大学、東京大学)は、環境中の微生物を解析したメタゲノム由来のゲノム配列(MAG: Metagenome-Assembled Genomes)を公共の塩基配列リポジトリから網羅的に収集し、環境や系統・遺伝子機能等、様々な情報を付加した統合データベース「Microbiome Datahub」を開発・公開しました。本データベースは、公共の塩基配列リポジトリに蓄積された21万件以上のMAG配列に対し、統一された遺伝子予測、系統分類、遺伝子機能アノテーション、表現型予測および環境メタデータを付与したものであり、データ駆動型の微生物学や未知の有用タンパク質探索の基盤として貢献することが期待されます。本研究成果は、科学誌「Microbiome」に2026年3月16日に速報版が掲載されました。背景
環境中の微生物群集から丸ごとDNA配列を解読するメタゲノム解析技術の発展により、培養困難な微生物のメタゲノム由来ゲノム情報(MAG[用語1])が爆発的に増加しています。これらのデータは公共の塩基配列リポジトリ(INSD[用語2])に登録されていますが、「品質のばらつき」「環境メタデータ(生息場所)の未整理」「遺伝子情報の欠如や分類体系の不統一」といった課題があり、そのままではデータの検索や横断的な比較解析が困難でした。また、既存のMAGの二次データベース(MGnify、IMG/M、SPIRE等)は、登録されたリード配列から独自のパイプラインで「再アセンブリ(再構築)」を行っているため、原著論文で報告されたMAGとは配列が変わってしまい、原著論文の研究成果を正しく参照・評価できないという問題(再現性の喪失)がありました(図1)。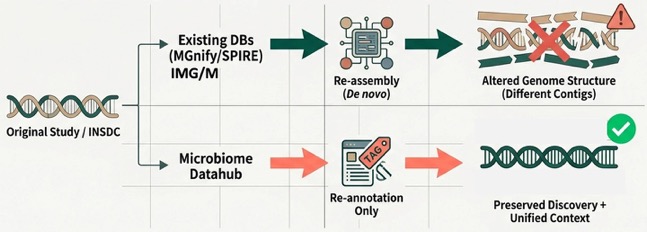
研究成果
本研究グループは、これらの課題を解決するため、公共リポジトリ中のMAGの配列はそのままに、メタデータとアノテーションのみを統一・高度化するアプローチを採用したMAGの統合データベース「Microbiome Datahub」を開発しました(図2)。主な特徴と成果は以下の通りです:
21万件超の大規模かつ高品質なMAGデータセットの構築: INSDから214,427件のMAGを収集しました。そのうち約17万件が「Completeness(完全性)>60% かつ Contamination(汚染度)<10%[用語3]」という高い品質基準を満たしており、公共リポジトリ中の大多数のMAGは高品質であることが確認されました。
独自のオントロジーを用いた環境情報の統一: 本研究グループで開発し公開している、微生物の生息環境を体系的に記述するオントロジー[用語4](MEO: Metagenome and Microbes Environmental Ontology[用語5])を用い、表記揺れの激しい環境メタデータを人手によるキュレーションも交えて「糞便(feces)」「活性汚泥(activated sludge)」「土壌(soil)」等123種類の環境に統一・整理しました。
27種類の表現型を予測: 系統名や16S rRNA遺伝子配列を用いた原核生物の表現型予測ツール「Bac2Feature[用語6]」を用いて、系統名から増殖速度、至適温度、至適pH等、全MAGに対して27の表現型を予測し、異なる環境間での微生物の生存戦略の違い(例:宿主関連環境の微生物は増殖速度が平均的に速い等)を示唆しました。
多数の新規性の高いタンパク質配列の発見: 超高速配列類似性検索ツール「PZLAST[用語7]」等を用いた解析により、MAGに含まれるタンパク質配列の約19%が既存のオーソログデータベース(MBGD[用語8])に相同性が無い新規性の高いタンパク質配列であることが明らかになりました。
今後の展開
Microbiome Datahubは、ウェブ上での高速検索やAPIアクセス、一括ダウンロードに対応しており、基礎的な微生物学研究から、タンパク質構造予測や有用酵素の探索等の応用研究まで、幅広く利用されることが期待されます。本プロジェクトは、今後も急増が予想される公共MAGデータを収載し整理・公開するデータベースとして、継続的な更新と拡張を予定しています。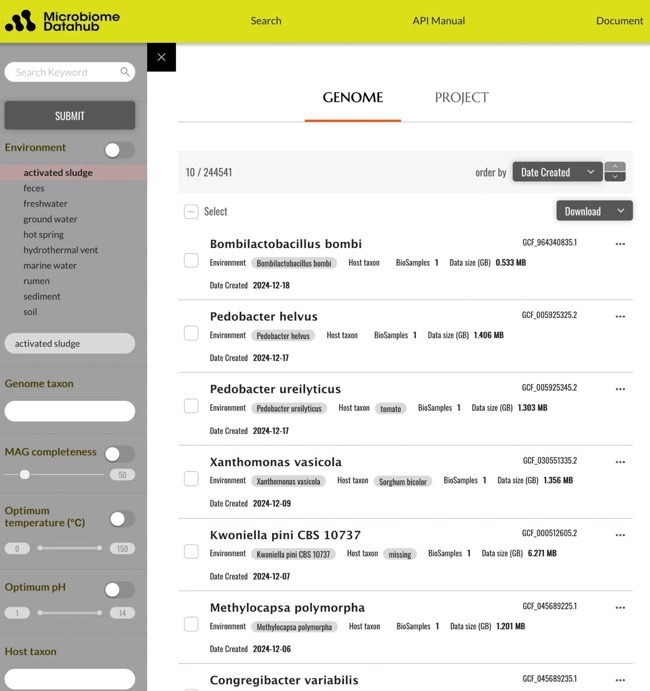
付記
本研究開発は、科学技術振興機構(JST)ライフサイエンスデータベース統合事業(統合化推進プログラム)(課題番号:JPMJND2206)の支援を受けて実施されました。用語説明
- [用語1]
- MAG:Metagenome Assembled Genomeの略称であり、メタゲノム配列をアセンブルして得られた長い配列(コンティグ)から、配列の連続塩基組成や配列の相対存在量等の情報をもとにコンティグをクラスタリング(binning)して得られる、仮想的なゲノム配列を指します。
- [用語2]
- INSD:International Nucleotide Sequence Databaseの略称であり、様々な生物の塩基配列データを蓄積し公開している公共の塩基配列リポジトリを指す。現在は遺伝研のDDBJ、ヨーロッパにあるEMBL-EBIのENA、アメリカのNCBIの3機関で運営されています。
- [用語3]
- CompletenessとContamination:原核生物のゲノムやMAGにおいて、配列の品質評価に使用される指標。原核生物のゲノム中に通常1コピーのみ存在する必須遺伝子セットを用いて、どの程度セット中の遺伝子が揃っているか(Completeness)、およびどの程度重複してそれらの遺伝子を所持しているか(Contamination)を計算して%で表します。Completenessは100%に近いほど良く、Contaminationは0%に近いほど良い統計量です。これらの統計量は、CheckMやCheckM2等のツールを用いてゲノムやMAGごとに計算することが可能です。
- [用語4]
- オントロジー:ある分野の概念(ものや事柄)と、それらの関係性を体系的に定義した知識の構造。遺伝子の機能についてのオントロジー Gene Ontology等が生物学分野では代表的なオントロジーです。
- [用語5]
- MEO:Metagenome and Microbes Environmental Ontologyの略称であり、生物の環境を記述したEnvironmental Ontologyの一部を利用した上で、微生物の生息環境に特化した語彙を追加し、クラス構造を大きく改変した、微生物特化の環境オントロジーです。遺伝研の森グループが中心になって開発し、生命科学分野のオントロジーの国際的なポータルサイト、BioPortalにて公開されています。
- [用語6]
- Bac2Feature:標準化された微生物の特性や形質に関するデータセットに様々な予測手法を適用し、16S rRNA遺伝子配列や系統名から、細胞形態、グラム染色性、胞子形成能や運動性の有無、ゲノムの特徴、生育条件等等、その微生物の様々な表現型を予測するツールです。京都大学の松井グループが開発し公開しています。
- [用語7]
- PZLAST:メタゲノム由来の大量のタンパク質のアミノ酸配列に対して、専用のスーパーコンピュータを用いて超高速にアミノ酸対アミノ酸の配列類似性検索を行うことが可能な検索ツールです。森グループが中心になって開発し公開しています。
- [用語8]
- MBGD:主に微生物を対象として、遺伝子のオーソログ関係を、タンパク質をより詳細な機能単位であるドメインに分割した上でクラスタリングを行って推定し、オーソログクラスタとして整理したデータベースです。MBGDは基礎生物学研究所の内山グループが構築・運営しています。
論文情報
- 掲載誌:
- Microbiome
- タイトル:
- Microbiome Datahub: an open-access platform integrating environmental metadata, taxonomy, and functional annotation for comprehensive metagenome-assembled genome datasets
- 著者:
- Hiroshi Mori, Takatomo Fujisawa, Koichi Higashi, Yasuhiro Tanizawa, Zenichi Nakagawa, Hiroyo Nishide, Masaki Fujiyoshi, Yasukazu Nakamura, Ikuo Uchiyama, Motomu Matsui, Takuji Yamada
- DOI:
- 10.1186/s40168-026-02385-x
Microbiome Datahub
全ゲノム配列、メタデータ、機能アノテーションデータは一括ダウンロード(Zenodo等のwebサイト)でも提供されています。
関連リンク
プレスリリース メタゲノム由来ゲノムを収集・整理した統合データベース「Microbiome Datahub」を開発—21万ゲノム以上のMAG配列と環境・機能情報を統合し、微生物研究を加速—(PDF)日本伝統漬物「しば漬け」から発見:新規グリセロール含有菌体外多糖を産生する乳酸菌株を同定 | Science Tokyoニュース
ゾウの腸内細菌がコーヒー豆を発酵し味を変える可能性 | Science Tokyoニュース
麹菌の菌核内部に未知の構造体を発見 | Science Tokyoニュース
漬物由来の乳酸菌が持つ「免疫機能を調節する力」を解明 | Science Tokyoニュース
オーファン酵素遺伝子を探索するための深層学習ベースの 計算手法「DeepES」を開発 | Science Tokyoニュース
腸内細菌が成人T細胞白血病リンパ腫の進行に与える影響 | Science Tokyoニュース
腸内細菌の代謝経路データベース「Enteropathway」を公開 | Science Tokyoニュース
リンチ症候群患者の大腸がんと腸内細菌の関連性の解明|旧・東京工業大学
ポリープの大腸がん化に腸内細菌が関係していた|旧・東京工業大学
Explainable AI(説明可能なAI)の活用による腸内細菌に基づく大腸がんの詳細な分類を実現|旧・東京工業大学
焼酎黒麹の白色化によって起こる遺伝子変異|旧・東京工業大学
塩から始まる微生物群集のダイナミクス|旧・東京工業大学
ぬか漬けたくあんを作る発酵微生物とおいしさのひみつ|旧・東京工業大学
胃切除術による腸内環境の変化を解明|旧・東京工業大学
メタゲノム・メタボローム解析により大腸がん発症関連細菌を特定|旧・東京工業大学
腸内細菌叢(腸内フローラ)のメタゲノム解析による発がん研究の加速に期待|旧・東京工業大学
腸内に住む菌の研究で大腸がんの早期発見法が見えてきた — 山田拓司|旧・東京工業大学
山田 拓司 Takuji Yamada | Science Tokyo研究情報データベース(理工学系)
山田研究室
生命理工学院 生命理工学系
生命理工学院
国立遺伝学研究所
基礎生物学研究所
京都大学
東京大学
取材申し込みページ
問い合わせ先
東京科学大学 生命理工学院 生命理工学系教授 山田 拓司
- contact@mail.comp.life.isct.ac.jp
- Tel
- 03-5734-3629
- FAX
- 03-5734-3591
取材申し込み
東京科学大学 総務企画部 広報課- media@adm.isct.ac.jp
- Tel
- 03-5734-2975
- FAX
- 03-5734-3661
情報・システム研究機構 国立遺伝学研究所 広報室
- prkoho@nig.ac.jp
- Tel
- 055-981-5873