 北陸先端科学技術大学院大学 研究
北陸先端科学技術大学院大学 研究大規模言語モデルの効率的な知識"忘却"技術を提案
-安全なAIの実現に大きな一歩-
【産学連携対象 全学共通分野 Discovery Saga】
【Sagaキーワード】
プレスリリース
研究のポイント
安全なAIの実現には、大規模言語モデル (LLM) が学習した有害知識を消去する「知識忘却」技術が求められています。RMUと呼ばれる従来の方法は高い忘却性能が確認されている一方、その動作原理や最適化方法には未解明の部分が多く、手探りによる最適化が必要でした。
本研究では、RMUを理論的・経験的に詳細に分析し、従来とほぼ同等の忘却性能を維持しながら最適化を自動で調整できるようにし、適用コストを大幅に削減することに成功しました。
| 北陸先端科学技術大学院大学(学長:寺野稔、石川県能美市)コンピューティング科学研究領域の井之上直也准教授の研究グループは、大規模言語モデルに内在する有害知識を取り除く手法Representation Misdirection for Unlearning(RMU)の動作原理の理論的・実証的な解明を進め、従来は手探りで調整していたランダムさの度合いを自動で調整できるようにして、RMUの最適化コストを大幅に削減することに成功しました。この研究により、モデルが生成する誤情報や危険情報などの有害情報を効果的に抑制でき、安全なAIの実現に大きく貢献することが期待されます。 |
【研究背景と内容】
近年、あらゆる分野で大規模言語モデル(LLM)の活用が進み、膨大なテキストデータを学習して多様かつ高度な回答を提供できるようになりました。医療や金融、教育など多岐にわたる領域への導入が検討されていますが、一方でLLMが学習したデータに機密情報や危険・有害な知識が含まれると、それらを意図せず出力してしまう恐れがあり、安全性の問題が指摘されています。こうした課題に対応するため、LLMに含まれる特定の知識だけを選択的に忘却させるUnlearningという技術が注目を集めています。
最近では、忘却対象となる知識に関連するLLMの内部表現をランダム化して、モデルがその知識を回答に活用できなくするRepresentation Misdirection for Unlearning(RMU)という手法が提案され、有望視されてきました。しかし、RMUの理論的な動作原理は十分に解明されておらず、効果を最大化するためには大きな計算リソースを割き、忘却対象のLLMや知識に応じて手探りで最適化を行う必要があることが大きなボトルネックでした。
本研究では、RMUを理論面と実データの両面から詳細に分析し、改良版であるAdaptive RMUを提案しました。Adaptive RMUは、これまで手探りで調整していたランダムネスの制御パラメータを自動化し、最適化コストを大幅に削減することに成功しています。また、RMUと遜色ない忘却性能を示しながら、LLMの一般的な言語理解能力をほとんど損なわず(図1(a))、有害情報に関する質問への正答率を大幅に低下させる効果(図1(b)(c))を実証しました。さらに、忘却後のLLMから有害知識を抜き出そうとする「知識復元攻撃」に対しても高い防御性能を示し、モデル内部に残る有害知識の抽出を大幅に困難にすることが理論的に確認されています。
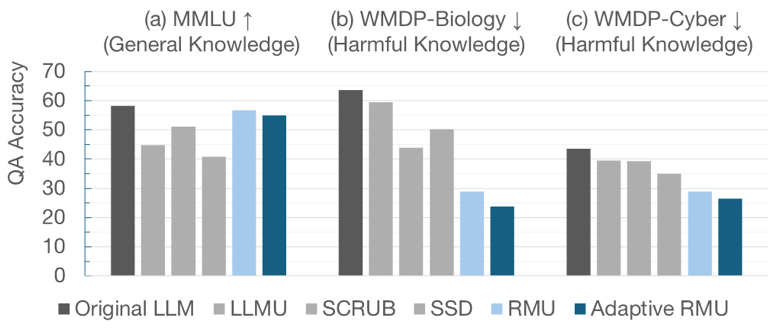
図1:知識忘却前の正答率(Original LLM)と、各種手法による知識忘却後の正答率の比較。
(a):一般知識に関する質問(変化が少ないほど良い)。(b)(c):有害知識に関する質問(低いほど良い)。
本研究の成果により、チャットボットや自動応答システムなどLLMを活用するあらゆるサービスにおいて、個人情報や機密情報の漏えいリスクを低減し、安全で信頼できるAI社会の実現に向けて大きな一歩となると期待されます。
本成果は、人工知能分野のトップ国際会議であるAAAI 2025にフルペーパー論文として採択され、さらに採択論文の約20%のみが選ばれる口頭発表として発表されました。また、本研究は、中島記念国際交流財団およびJST創発的研究支援事業(JPMJFR232K)の支援を受けて実施されました。
論文情報
| 掲載誌 | Proceedings of the AAAI Conference on Artificial Intelligence, 39 |
| 論文題目 | On Effects of Steering Latent Representation for Large Language Model Unlearning |
| 著者 | Dang Huu-Tien, Trung-Tin Pham, Hoang Thanh-Tung, Naoya Inoue |
| 掲載日 | 2025年4月11日 |
| DOI | https://doi.org/10.1609/aaai.v39i22.34544 |
令和7年4月30日